Information for Authors of Innovative Modules
The information on this page is explicitly aimed at the authors of innovative modules. In the following, innovative modules are abbreviated as “Inno-Modules”.
Questionnaire development
In order for a researcher’s Inno-Module to have a chance of being included in the SOEP-IS questionnaire, it must be submitted as part of the official SOEP-IS call for proposals. All relevant information about the call can be found at the website of the latest call for submissions. Please note that the process, the deadlines, and guidelines for the call may change from year to year. The most up-to-date information should be obtained from the corresponding website. Here, we are providing only general information and examples from recent years for basic informational purposes.
Below you can find a graphical overview of the questionnaire development process, including the data collection phase. The ‘syear’ serves as a placeholder for any typical survey year in which a SOEP-IS survey is conducted. For example, if we were to consider the survey year 2023, the two preceding years would logically be 2022 and 2021.
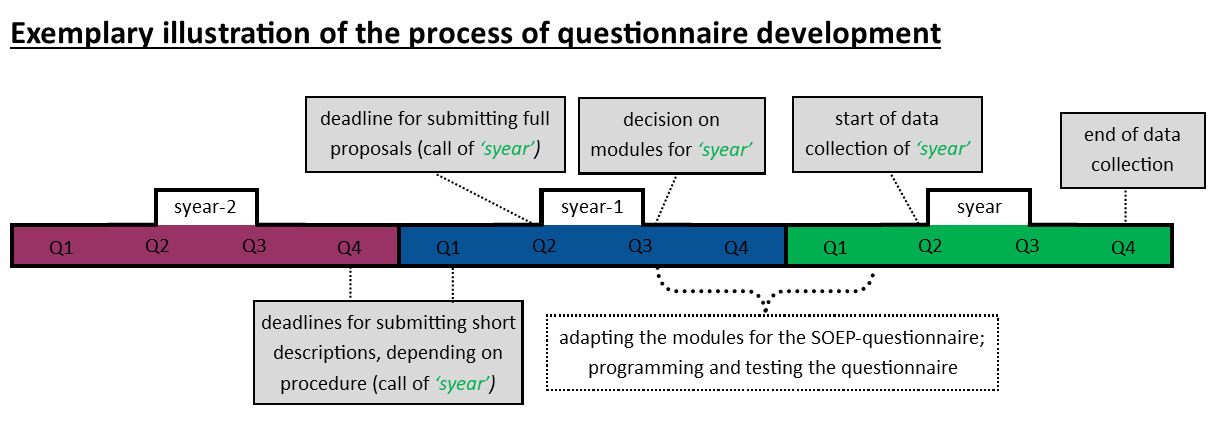
Please note that the time schedule for the call and the survey may change. This example is only intended as a general orientation. For detailed information on the survey years please see the overview of the Survey Periods and the respective Wave Reports.
Further information on how and when the survey data collected is made available to the respective authors of the Inno-Modules and to the scientific community can be found below on this page.
Structure of Raw-Data delivery
As the author of an implemented Inno-Module, you will not only receive the normal Data Distribution File of the SOEP-IS but also a minimally edited version of the raw data of the year in which your module was surveyed. This is because the generation of the official Data Distribution File takes a certain amount of time. But by receiving the raw data you can work shortly after the survey has been completed and thus use the data from your module without having to wait for the official release of the data. However, there are a few aspects associated with the use of raw data that should be known and taken into account.
Important Note: The term “raw data” in this context does not refer to the same as in the SOEP-Core. While in SOEP-Core the processed cross-sectional data is referred to as “raw”, in SOEP-IS this is actually almost unprocessed raw data that we receive from our study institute. Although this is also cross-sectional data, it is only subjected to a data check and minimal editing. The datasets are only forwarded in this form to the authors of the innovative modules so that they can work with them at an early stage. For the official Data Distribution File, the datasets are integrated into the long datasets in a user-friendly way and published exclusively in this optimized format.
In the raw-data delivery we only provide the datasets of the current survey year. The data of the official Data Distribution File has to be ordered separately and will not be included. However, all the provided datasets in the raw-data delivery include the needed identifiers to correctly merge or append the data with the Data Distribution File.
On the first look, the structure of raw-data differs from the official data distribution file. Below you can find a screenshot showing an example of a raw-data delivery (top-level folder):

The included readme provides a short overview of the included files and may contain further important information. The dataset(s) in the top-level folder contain the respective variables from the innovative module of the author(s). The datasets of innovative modules from other authors are not included. The “SOEP data” folder contains the rest of the survey data as well as the questionnaire PDFs (English and German):
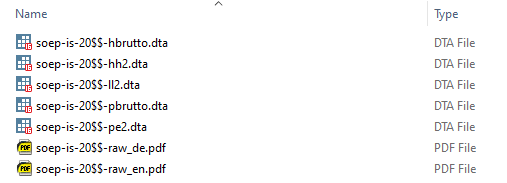
The German questionnaire is the one that was actually used for the survey. The English translation is only created for documentation purposes. The following table provides a short overview of the datasets in this “SOEP data” folder:
Dataset Name |
Explanation |
SUF equivalent (long data) |
|---|---|---|
soep-is-20$$-hbrutto |
Gross Dataset on household level |
hbrutto |
soep-is-20$$-pbrutto |
Gross Dataset on individual level |
pbrutto |
soep-is-20$$-hh2 |
Dataset from Household Questionnaire |
hl |
soep-is-20$$-ll2 |
Dataset from Biography Questionnaire |
biol |
soep-is-20$$-pe2 |
Dataset from Individual Questionnaire |
pl |
Provided the data from the official Data Distribution File is already available, the raw datasets can be appended or merged with the corresponding long datasets in order to add the new years to them and receive a long dataset.
It is also important to understand that the raw dataset of the biography questionnaire (“ll2”) only includes the individuals who answered this questionnaire in this wave. The data of individuals who have already completed the questionnaire in previous waves is only in the “biol” dataset of the Data Distribution File. For more information regarding the biography questionnaire see Individual Questionnaire.
Limitations of Raw-Data
Missing variables
Generally, we do not provide all the variables with the raw data that are available to us. This usually has to do with the fact that we want to keep the data as clear and easy to use as possible and do not integrate any variables that require additional data protection. Nevertheless, there is some information that we can provide on request or generate relatively fast. This includes, for example, basic regional data (such as federal states or east/west affiliation), durations of the items, open ended questions (string variables), date of the interviews, etc.
Cross-study variable names and labels
We aim to maintain the highest possible comparability with the SOEP Core in the SOEP-IS data. This is why we use identical variable names and the same variable labels wherever possible. In the case of versioned variables, this means that the version designation of the SOEP-Core is adopted, regardless of the actual version in the SOEP-IS. For more information an that please see “What do the suffixes “_v1”, “_v2”, or “_h” in variable names mean?”.
Generated data, weighting and official release
As already mentioned above, the raw-data delivery only provides the datasets of the current survey year without any generated data. This means that no weights or imputed variables are included in the raw-data. If it is necessary to merge the raw data with generated variables of the same survey year or to run weighted analyses, it is necessary to wait for the official release of the data. The generation process usually takes about a year. The data release is always scheduled approximately for the second quarter of the next year. However, due to the data embargo for the data of inno modules (see Inno Dataset), these variables will not be part of the official Data Distribution File. It is therefore necessary to merge the raw data with the Data Distribution File of the next year in order to use the weights of the same survey year. After the one-year embargo, the data will then be published as part of the normal Scientific Use File of the next survey year. In this respect, the data of innovative modules from a survey year is always published approximately three years after the start of the actual data collection process.
Exemplary process of data collection and publication
Below you can find a graphical overview of the data distribution process, including the data collection phase. The ‘syear’ serves as a placeholder for any typical survey year in which a SOEP-IS survey is conducted. For example, if we were to consider the survey year 2023, the next three years would logically be 2024, 2025 and 2026.
2nd quarter ‘syear’: Start of data collection
4th quarter ‘syear’: End of data collection
1st quarter ‘syear’+1: transmission of the raw data to the authors of the inno modules
2nd quarter ‘syear’+2: publication of the official Data Distribution File of survey year ‘syear’ without the inno module data of ‘syear’, but with generated variables, imputation and weights
2nd quarter ‘syear’+3: publication of the official Data Distribution File of survey year ‘syear’+1 together with the inno module data of survey year ‘syear’ (one-year embargo)
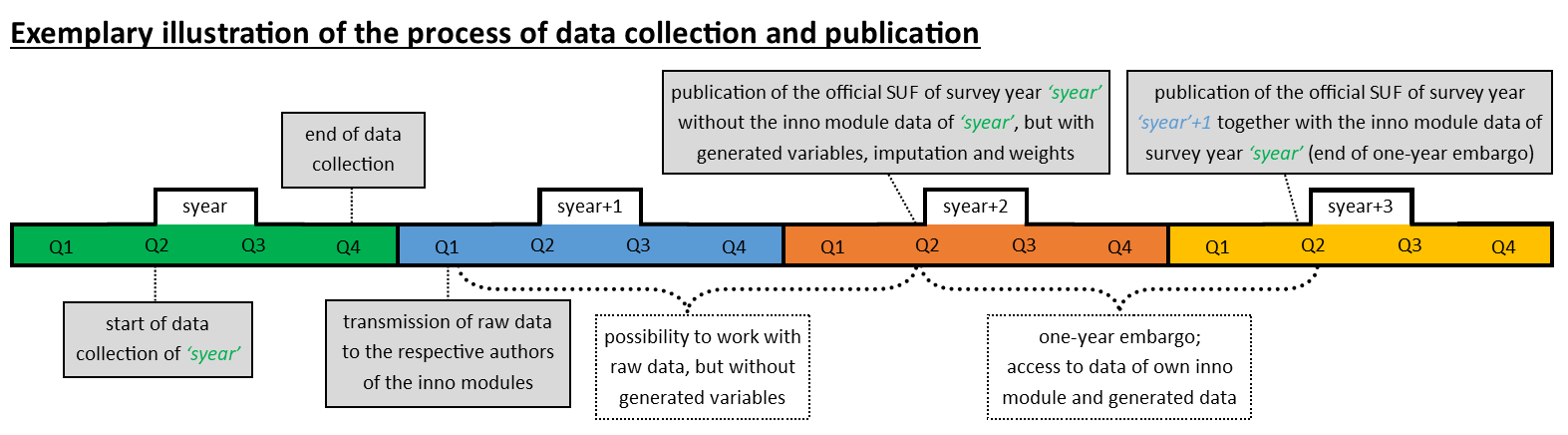
Please note that the time schedule for the survey may change. This example is only intended as a general orientation. For detailed information on the survey years please see the overview of the Survey Periods and the respective Wave Reports.